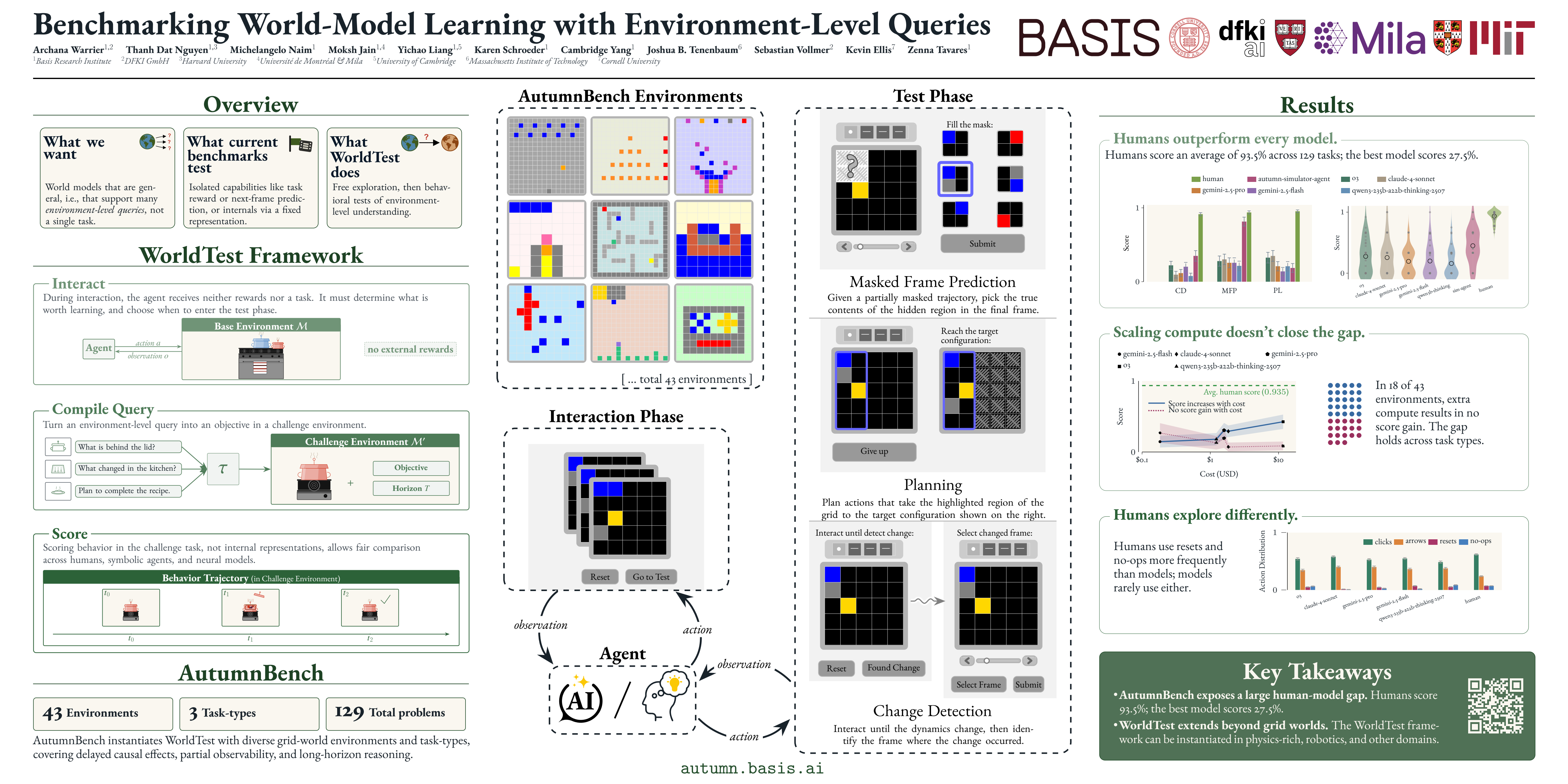
We introduce WorldTest, a framework for evaluating world model learning through environment-level queries about full dynamics, not single trajectories. AutumnBench, instantiated under WorldTest, exposes large human-LLM gaps in world-model building.
We introduce WorldTest, a representation-agnostic protocol for evaluating world-model learning in AI agents. WorldTest moves beyond next-frame prediction by posing environment-level queries — asking whether an agent can predict unobserved states, plan action sequences toward goals, and detect changes in causal dynamics.
We instantiate WorldTest with AutumnBench, a suite of 43 interactive grid-world environments and 129 tasks across three families: masked-frame prediction, planning, and predicting changes to causal dynamics. We evaluated 517 human participants and three frontier reasoning models on AutumnBench. Humans outperform the models, and scaling compute improves performance only in some environments — exposing substantial headroom in world-model learning (Warrier et al., 2026).
PS: The games are fun to play — try them at autumn.basis.ai!
Try it yourself
Interactive task selector — play directly here.
Example human vs AI interactions
Human
Claude 4 Sonnet
Gemini 2.5 Pro
o3
References
2026
ICML
Benchmarking World-Model Learning with Environment-Level Queries
Archana Warrier, Dat Nguyen, Michelangelo Naim, and 8 more authors
In Forty-third International Conference on Machine Learning, 2026
World models are central to building AI agents capable of flexible reasoning and planning. Yet current evaluations (i) test only properties measurable from observed interactions, such as next-frame prediction or task return, and (ii) do not test whether a learned model supports diverse queries about the environment. In contrast, humans build general-purpose models that can answer many different questions about an environment—including questions that require understanding global structure and counterfactual consequences. We propose WorldTest: a protocol for evaluating whether agents learn models that support multiple environment-level queries—questions whose answers depend on properties of the full environment, not just observed trajectories. Individually, these queries can target properties (e.g., reachability or the effects of interventions) that no single rollout distribution determines. Collectively, they assess model generality across query types. We instantiate WorldTest as AutumnBench, a benchmark of 43 interactive grid-world environments and 129 tasks across three query families for both humans and learning agents. Experiments with 517 human participants and five frontier models on AutumnBench show that humans substantially outperform these models, a gap we attribute to differences in exploration and belief updating.
@inproceedings{warrier2026benchmarking,title={Benchmarking World-Model Learning with Environment-Level Queries},author={Warrier, Archana and Nguyen, Dat and Naim, Michelangelo and Jain, Moksh and Liang, Yichao and Schroeder, Karen and Yang, Cambridge and Tenenbaum, Joshua and Vollmer, Sebastian and Ellis, Kevin and Tavares, Zenna},booktitle={Forty-third International Conference on Machine Learning},year={2026},url={https://openreview.net/forum?id=Ny6UYZ8ysN}}